Overcoming the challenge of heterogeneity in healthcare
The treatment landscape in dermato-oncology has been growing rapidly over the past few years. According to a study published in 2019, there were almost 200 clinical trials registered for Melanoma therapies in 2018. The majority of these clinical trials focus was the effectiveness of monoclonal antibody therapies and targeted therapies. This surge in new therapies poses a challenge for clinicians as not all patients respond alike so there is a need to optimize treatment assignment. To tackle this challenge, researchers have begun to explore the use of machine learning (‘ML’) models, trained on standard dermoscopic images, to identify predictive features of melanoma.
The first step to training such a model is to collect skin images and the patient’s corresponding clinical information. One way to collect these images is to collaborate with a single hospital to access the required data. Once the model has been trained and evaluated, one can validate it, both prospectively and externally, with data from other hospitals. When implementing this validation step, a drop in model performance is often observed. This lack of generalization capability is due to data heterogeneity. In this blog article, we explain the concept of data heterogeneity and emphasize the need for training models on multiple centers to overcome it.
What is data heterogeneity?
Data heterogeneity refers to data with a great variety of different data distributions. Heterogeneity often appears in healthcare data because patients’ populations, environment, procedures, and treatment protocols in medical centers vary. For instance, every time a medic collects data from a patient (such as blood type, Computed Tomography (‘CT’) scan or blood pressure), irregularities arise. These differences create heterogeneity in our data.
Medical data heterogeneity can be classified into two main categories:
1. Heterogeneity stemming from standardization and interoperability
This heterogeneity occurs from technical and clinical disparities across hospitals and research centers.
Technological heterogeneity
Technological heterogeneity refers to the differences in how medical centers measure and record their data. Centers use machines from different manufacturers, record their data with inconsistent units and labels, and have many other documentation disparities. If a Hospital based in London uses dermatoscopes while a New York Hospital uses standard photos, technical heterogeneity will arise.
Clinical practice
Clinical heterogeneity occurs in data because medical practices differ across countries. For instance, a doctor working in our London hospital may use a specific protocol to treat a melanoma patient. In contrast, a doctor in the New York hospital may have different conventions to treat the same patient.
2. Heterogeneity related to core differences between patients and their environments
This heterogeneity arises from variations in the patient population and the hospital environment.
Population heterogeneity
Population heterogeneity refers to the differences in genetic heritage, age, and individual socioeconomic variables of patients. Diversity in data sampling is essential. If we base our model only on Caucasian patients’ images, this model will not work well on people with different skin colors.
Environmental heterogeneity
Environmental heterogeneity comes from the physical location of different hospitals. The weather, air quality, temperature, and seasons of various regions in the world can cause heterogeneity in datasets. For example, we must recognize that the amount of sun to which patients are exposed will affect the risk of melanoma and influence our model.
Multi-centric studies and heterogeneity: Is heterogeneity helpful or harmful for creating an AI model?
Imagine we trained a ML model to predict patient outcomes based on standard skin pictures from our London hospital. Unfortunately, all the images taken in this hospital from seriously ill patients were taken with a stronger flash than what was used to photograph smaller-grade melanomas. Therefore, the resulting model is likely to have learned a spurious correlation between lightning and the type of melanoma. This means it will not generalize to data from other hospitals, such as the hospital in New York.
To solve this issue, we must train our model on a multi-centric dataset. This involves us including additional data samples from other hospitals where this spurious correlation does not exist. The different datasets will train the model to realize that the average image brightness does not determine whether a lesion is benign or malignant. The model will then discount image type as an essential factor and instead look at other, more crucial data differences. The image type’s technological heterogeneity will become “background noise,” since the algorithm has been forced to work harder to find features that affect the label (benign or malignant melanoma).
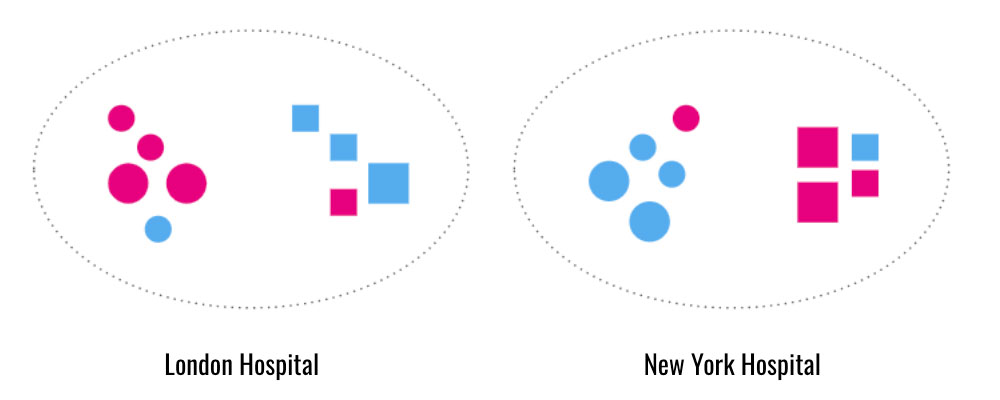
Let us look at our two hospitals in London and New York again
Each hospital has one dataset of both squares and circles. In the London hospital dataset, most of the circles are pink, and the squares are blue. In the New York hospital dataset, most of the circles are blue, and the squares are pink. If we train our model exclusively on the London dataset to classify shape, our model will create a spurious correlation between color and shape. This model will proxy pink for circles and blue for squares. If we try to use this model to predict the shapes in the dataset from New York, it will misidentify the shapes. It will predict that just because a shape is pink, it must also be a circle. The same phenomenon will occur if we train our model only on the New York dataset and apply it to London’s dataset.
To solve this problem, we must train our model on both datasets. In this scenario, the model will realize that color does not indicate shape. The model will be forced to find different features to distinguish circles from squares. This model will perform better on both datasets.
These scenarios lead us to a critical point: the more diversity in our samples, the less likely our model will encounter unfamiliar data types.
Heterogeneity in training data helps models adapt to real-world settings
However, we must consider one crucial aspect of heterogeneity—just because heterogeneity helps build a robust model, it does not mean that all data differences should affect the output of our model. The heterogeneity that should distinguish our output depends on our goal. In this case, we want the model to take the core heterogeneity of patients (such as different skin types and amount of sun exposure in certain environments) into account when searching for features predictive of melanoma. Unlike the differences in image type or orientation, these dissimilarities are essential for the model to identify melanoma on all patients correctly. We still want other types of heterogeneity present in our training data. Still, the model’s output should only be based on heterogeneous features that impact whether a lesion should be classified as melanoma.
Data heterogeneity is fundamental in training a ML model that would generalize well across patient populations, environments, medical procedures, and treatment protocols. Multi-centric studies are crucial to capture this heterogeneity
In order to carry out such multicentric studies, data pooling isn’t always possible. Data pooling refers to the collection of datasets from different centers into a single location. While this simplifies the harmonization and analysis of the datasets, it can compromise individual data records’ privacy. Furthermore, data owners are not necessarily willing to pool their datasets. Especially if the other parties involved are their main competitors.
At Owkin, we leverage data heterogeneity from multi-centric studies through federated learning
In the federated learning (‘FL’) setting, only ML models travel between the different centers, while the data itself never leaves its original center. This privacy-preserving approach makes it possible to build robust ML models from heterogeneous data. Think of the benefit of medical research and the impact on patient outcomes if we can leverage worldwide data without the downside of transferring personal information. This is our mission at Owkin. We are building a Data Platform that is fueling collaborative research worldwide while preserving patient privacy and data security.
Handling the pitfalls of heterogeneity, including data harmonization, is no simple task in a federated setting. Still, it is imperative for groundbreaking medical discoveries. Owkin has the right combination of expertise and technologies to master it. The FL team at Owkin is currently building a federated data science workflow explicitly designed for FL. This involves a mix of technological breakthroughs and best practices. Stay tuned for our upcoming blog post in the FL series on overcoming the challenges associated with heterogeneity in an FL setting.
Authors


Testimonial
